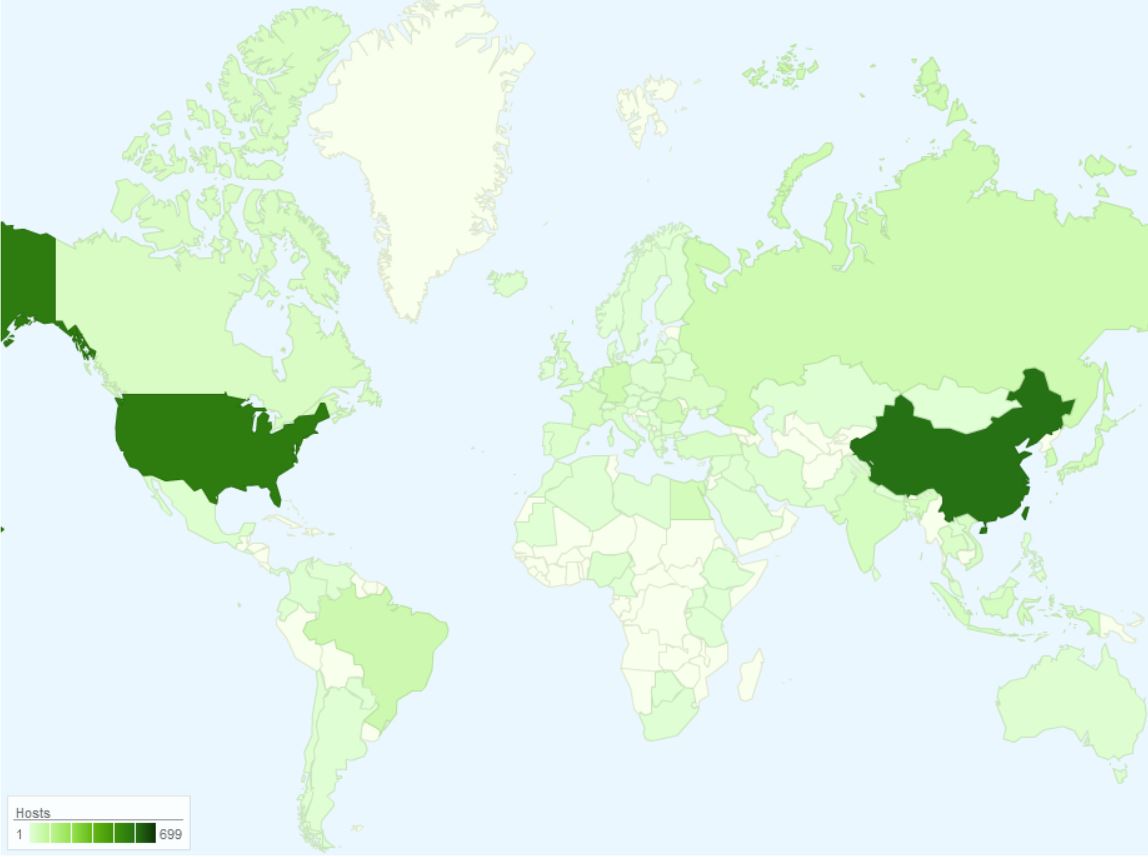
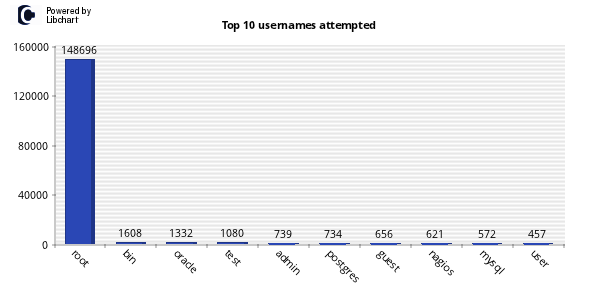
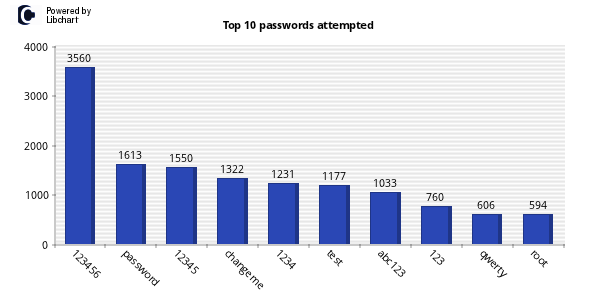
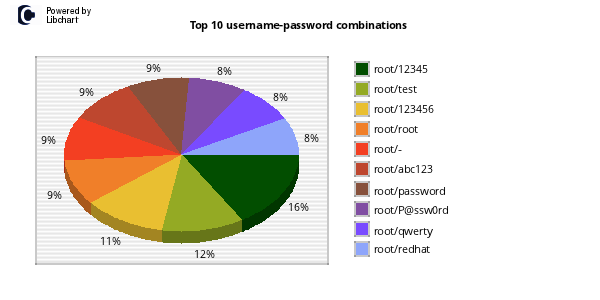
One of my favorite uses of kippo data is to generate wordlists from login attempts. I wrote a quick script to parse the kippo logs and pull out all passwords and unique them into a wordlist. Feel free to grab. Additionally I made the wordlists available for download.
Two items of note here are that over 60% of password attempts were 1-8 characters. 40% of attempts were for lowercase alpha characters only. The most used password was 123456. This is the default pass for Kippo.
If a user attempts to create an account or change the root password in a Kippo session those passwords are captured and added to the allowed credentials list. The following credentials were created:
�AWSWeb:~# adduser
adduser: Only one or two names allowed.
AWSWeb:~# useradd
adduser: Only one or two names allowed.
AWSWeb:~# ls
AWSWeb:~# pwd
root
AWSWeb:~# cd /�[1D�[1P�[1D�[1P�[1D�[1P�[1D�[1Pcat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
lp:x:7:7:lp:/var/spool/lpd:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
uucp:x:10:10:uucp:/var/spool/uucp:/bin/sh
proxy:x:13:13:proxy:/bin:/bin/sh
www-data:x:33:33:www-data:/var/www:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh
list:x:38:38:Mailing List Manager:/var/list:/bin/sh
irc:x:39:39:ircd:/var/run/ircd:/bin/sh
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/bin/sh
nobody:x:65534:65534:nobody:/nonexistent:/bin/sh
libuuid:x:100:101::/var/lib/libuuid:/bin/sh
richard:x:1000:1000:richard,,,:/home/richard:/bin/bash
sshd:x:101:65534::/var/run/sshd:/usr/sbin/nologin
AWSWeb:~# user
bash: user: command not found
AWSWeb:~# adduser obz
Adding user `obz' ...
Adding new group `obz' (1001) ...
Adding new user `obz' (1001) with group `obz' ...
Creating home directory `/home/obz' ...
Copying files from `/etc/skel' ...
Password:
Password again:
Changing the user information for obz
Enter the new value, or press ENTER for the default
Username []:
Must enter a value!
Username []: obz
Full Name []: l�[1D�[1Padmin obz
Room Number []: 1
Work Phone []: 1234567890
Home Phone []:
Must enter a value!
Home Phone []: 0
Mobile Phone []: 0
Country []: cn
City []: xang
Language []: mand
Favorite movie []: 1
Other []: 1
Is the information correct? [Y/n] y
ERROR: Some of the information you entered is invalid
Deleting user `obz' ...
Deleting group `obz' (1001) ...
Deleting home directory `/home/obz' ...
Try again? [Y/n] y
Changing the user information for obz
Enter the new value, or press ENTER for the default
Username []: obx
Full Name []: obx toor
Room Number []: 1
Work Phone []: 1�[1D�[1P9089543121
Home Phone []: 9089342135
Mobile Phone []: 9089439012
Country []: cn
City []: xang
Language []: man�[1D�[1P�[1D�[1P�[1D�[1Penglish
Favorite movie []: one
Other []: two�[1D�[1P�[1D�[1P�[1D�[1Pfour
Is the information correct? [Y/n] y
ERROR: Some of the information you entered is invalid
Deleting user `obz' ...
Deleting group `obz' (1001) ...
Deleting home directory `/home/obz' ...
Try again? [Y/n] n
AWSWeb:~# cat �adduser obz� user� cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
lp:x:7:7:lp:/var/spool/lpd:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
uucp:x:10:10:uucp:/var/spool/uucp:/bin/sh
proxy:x:13:13:proxy:/bin:/bin/sh
www-data:x:33:33:www-data:/var/www:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh
list:x:38:38:Mailing List Manager:/var/list:/bin/sh
irc:x:39:39:ircd:/var/run/ircd:/bin/sh
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/bin/sh
nobody:x:65534:65534:nobody:/nonexistent:/bin/sh
libuuid:x:100:101::/var/lib/libuuid:/bin/sh
richard:x:1000:1000:richard,,,:/home/richard:/bin/bash
sshd:x:101:65534::/var/run/sshd:/usr/sbin/nologin
AWSWeb:~# cat /etc/shadow
cat: /etc/shadow: No such file or directory
AWSWeb:~# /etc/init.d\�[1D�[1P�[1D�[1PD/ssh start
bash: /etc/init.D/ssh: command not found
AWSWeb:~# �[K/etc/init.D/ssh start�[1D�[1D�[1D�[1D�[1D�[1D�[1D�[1D�[1D�[1D�[1D�[1Pd
bash: /etc/init.d/ssh: command not found
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~#
AWSWeb:~# exit
cConnection to server closed.
localhost:~# exit
Connection to server closed.
localhost:~# bye
bash: bye: command not found
localhost:~# exit
�Connection to server closed.
localhost:~# admin
bash: admin: command not found
localhost:~# su
localhost:~# ls -l
drwxr-xr-x 1 root root 4096 2013-02-03 17:11 .
drwxr-xr-x 1 root root 4096 2013-02-03 17:11 ..
drwxr-xr-x 1 root root 4096 2009-11-06 11:16 .debtags
-rw------- 1 root root 5515 2009-11-20 09:08 .viminfo
drwx------ 1 root root 4096 2009-11-06 11:13 .aptitude
-rw-r--r-- 1 root root 140 2009-11-06 11:09 .profile
-rw-r--r-- 1 root root 412 2009-11-06 11:09 .bashrc
localhost:~# pwd
/root
localhost:~# cd /
localhost:/# ls -l
drwxr-xr-x 1 root root 4096 2013-02-03 17:11 .
drwxr-xr-x 1 root root 4096 2013-02-03 17:11 ..
drwxr-xr-x 1 root root 0 2009-11-20 08:19 sys
drwxr-xr-x 1 root root 4096 2009-11-08 15:42 bin
drwxr-xr-x 1 root root 4096 2009-11-06 11:08 mnt
drwxr-xr-x 1 root root 4096 2009-11-06 11:08 media
lrwxrwxrwx 1 root root 25 2009-11-06 11:16 vmlinuz -> /boot/vmlinuz-2.6.26-2-686
drwxr-xr-x 1 root root 4096 2009-11-06 11:09 opt
lrwxrwxrwx 1 root root 11 2009-11-06 11:08 cdrom -> /media/cdrom0
drwxr-xr-x 1 root root 4096 2009-11-06 11:08 selinux
drwxrwxrwx 1 root root 4096 2009-11-20 08:19 tmp
dr-xr-xr-x 1 root root 0 2009-11-20 08:19 proc
drwxr-xr-x 1 root root 4096 2009-11-08 15:41 sbin
drwxr-xr-x 1 root root 4096 2009-11-20 08:20 etc
drwxr-xr-x 1 root root 3200 2009-11-20 08:20 dev
drwxr-xr-x 1 root root 4096 2009-11-06 11:09 srv
lrwxrwxrwx 1 root root 28 2009-11-06 11:16 initrd.img -> /boot/initrd.img-2.6.26-2-686
drwxr-xr-x 1 root root 4096 2009-11-08 15:46 lib
drwxr-xr-x 1 root root 4096 2009-11-06 11:22 home
drwxr-xr-x 1 root root 4096 2009-11-06 11:09 var
drwxr-xr-x 1 root root 4096 2009-11-08 15:46 usr
drwxr-xr-x 1 root root 4096 2009-11-08 15:39 boot
drwxr-xr-x 1 root root 4096 2009-11-20 09:08 root
drwx------ 1 root root 16384 2009-11-06 11:08 lost+found
localhost:/# cd /home
localhost:/home# ls -l
ldrwxr-xr-x 1 root root 4096 2013-02-03 17:11 .
drwxr-xr-x 1 root root 4096 2013-02-03 17:11 ..
drwxr-xr-x 1 1000 1000 4096 2009-11-06 11:22 richard
localhost:/home# exit
Connection to server closed.
localhost:~#
localhost:~#
localhost:~#
localhost:~#
localhost:~#
localhost:~#
localhost:~# ssh -D root@http://60.250.65.112/ 1337
�The authenticity of host '60.250.65.112 (60.250.65.112)' can't be established.
RSA key fingerprint is 9d:30:97:8a:9e:48:0d:de:04:8d:76:3a:7b:4b:30:f8.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '60.250.65.112' (RSA) to the list of known hosts.
root@60.250.65.112's password:
Linux localhost 2.6.26-2-686 #1 SMP Wed Nov 4 20:45:37 UTC 2009 i686
Last login: Sat Feb 2 07:07:11 2013 from 192.168.9.4
localhost:~# uname -a
Linux localhost 2.6.24-2-generic #1 SMP Thu Dec 20 17:36:12 GMT 2007 i686 GNU/Linux
localhost:~# pwd
/root
localhost:~# cd /
localhost:/# ls -l
drwxr-xr-x 1 root root 4096 2013-02-03 17:19 .
drwxr-xr-x 1 root root 4096 2013-02-03 17:19 ..
drwxr-xr-x 1 root root 0 2009-11-20 08:19 sys
drwxr-xr-x 1 root root 4096 2009-11-08 15:42 bin
drwxr-xr-x 1 root root 4096 2009-11-06 11:08 mnt
drwxr-xr-x 1 root root 4096 2009-11-06 11:08 media
lrwxrwxrwx 1 root root 25 2009-11-06 11:16 vmlinuz -> /boot/vmlinuz-2.6.26-2-686
drwxr-xr-x 1 root root 4096 2009-11-06 11:09 opt
lrwxrwxrwx 1 root root 11 2009-11-06 11:08 cdrom -> /media/cdrom0
drwxr-xr-x 1 root root 4096 2009-11-06 11:08 selinux
drwxrwxrwx 1 root root 4096 2009-11-20 08:19 tmp
dr-xr-xr-x 1 root root 0 2009-11-20 08:19 proc
drwxr-xr-x 1 root root 4096 2009-11-08 15:41 sbin
drwxr-xr-x 1 root root 4096 2009-11-20 08:20 etc
drwxr-xr-x 1 root root 3200 2009-11-20 08:20 dev
drwxr-xr-x 1 root root 4096 2009-11-06 11:09 srv
lrwxrwxrwx 1 root root 28 2009-11-06 11:16 initrd.img -> /boot/initrd.img-2.6.26-2-686
drwxr-xr-x 1 root root 4096 2009-11-08 15:46 lib
drwxr-xr-x 1 root root 4096 2009-11-06 11:22 home
drwxr-xr-x 1 root root 4096 2009-11-06 11:09 var
drwxr-xr-x 1 root root 4096 2009-11-08 15:46 usr
drwxr-xr-x 1 root root 4096 2009-11-08 15:39 boot
drwxr-xr-x 1 root root 4096 2009-11-20 09:08 root
drwx------ 1 root root 16384 2009-11-06 11:08 lost+found
localhost:/# cd /root
localhost:~# ls -l
ldrwxr-xr-x 1 root root 4096 2013-02-03 17:19 .
drwxr-xr-x 1 root root 4096 2013-02-03 17:19 ..
drwxr-xr-x 1 root root 4096 2009-11-06 11:16 .debtags
-rw------- 1 root root 5515 2009-11-20 09:08 .viminfo
drwx------ 1 root root 4096 2009-11-06 11:13 .aptitude
-rw-r--r-- 1 root root 140 2009-11-06 11:09 .profile
-rw-r--r-- 1 root root 412 2009-11-06 11:09 .bashrc
localhost:~# cd /ho�[1D�[1P�[1D�[1P�[1D�[1P�[1D�[1P�[1D�[1P�[1D�[1Pcd /home/
localhost:/home# ls -l
drwxr-xr-x 1 root root 4096 2013-02-03 17:20 .
drwxr-xr-x 1 root root 4096 2013-02-03 17:20 ..
drwxr-xr-x 1 1000 1000 4096 2009-11-06 11:22 richard
localhost:/home# exit
Connection to server closed.
localhost:~# exit
Connection to server closed.
localhost:~#
After a year with Kippo, I have learned a lot about what these basic attackers do when connecting to seemingly open ssh hosts. There is plenty more to learn though. I have some plans on building out a larger honeypot infrastructure, and automating some of the data collection and parsing. Additionally I would like to spend more time analyzing the sessions and malware for further trends. I'll keep you all posted!
 Network,
Network,