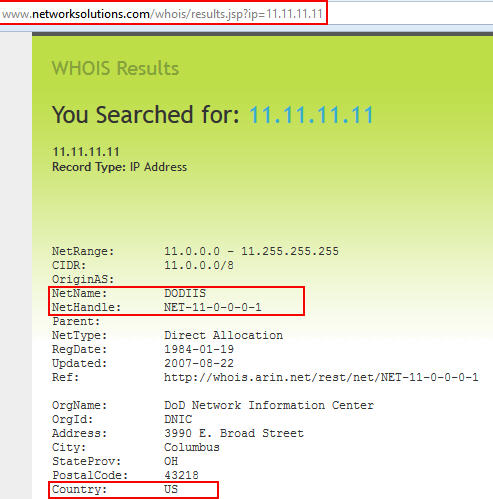
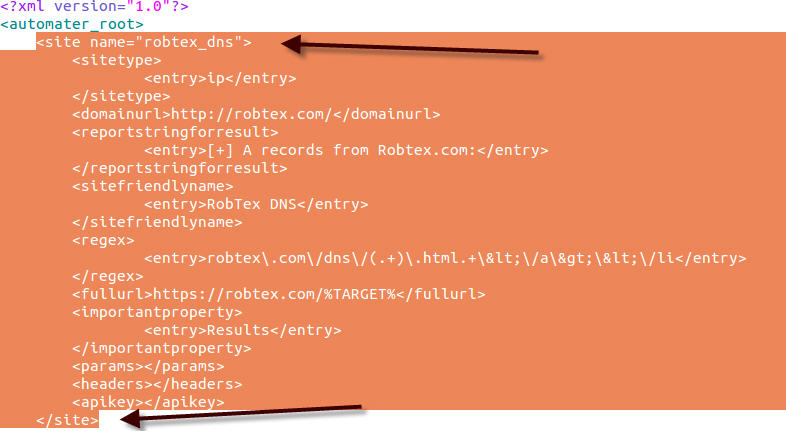
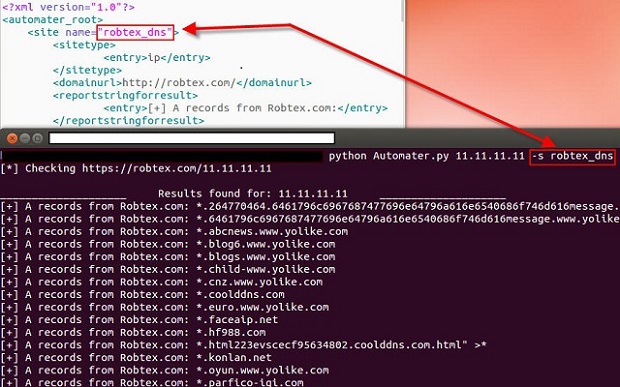
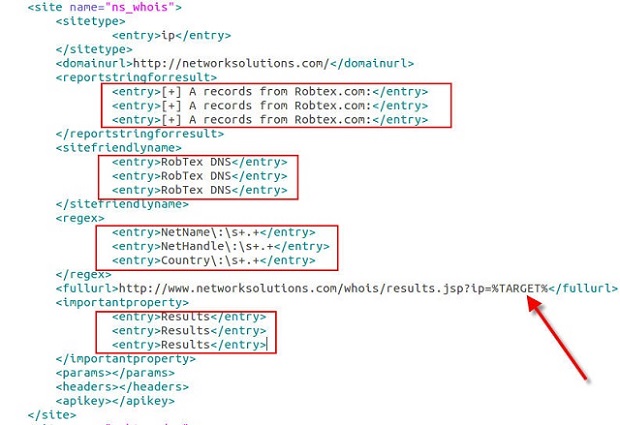
I was lucky enough to get a seat in the Volatility class a few weeks back. As I know many of you are interested in DFIR, especially as it pertains to memory analysis, I figured it would be worth writing a review of the class.

Exceeding Expectations
Before signing up for the class, I had spoken to a few folks who had attended previously. They all gave the class a big thumbs up, but I initially still had reservations. My main fear was that the class would just reinforce what I already knew. I did not want the class to be a "run the plugin" type of class. What I hoped for was a class that would teach me how the plugins worked while also teaching enough about the framework that I could start writing my own plugins. The material covered in the class far exceeded what I had hoped for. I learned about the volatility framework and how each of the plugins worked, but also learned much more such as Windows internals, memory internals, and some reverse engineering. Later in the article I will speak to some of the other topics that are covered as well.
Prerequisites / Target Audiences
Before delving too much into the course content, I think it is important to talk about some of the prerequisites for the class and understand who this course is for. I wouldn’t normally focus on this topic, but for this class I think it is vital that people understand what they are getting into. The listed prerequisites are:
• Some experience with the volatility framework
• Basic knowledge of digital investigation tools and techniques
• Comfortable with general troubleshooting in Windows and Linux
• Familiar with popular systems administrations tools like the SysInternals Utilities
• Comfortable with Windows and Linux command line
• Basic scripting knowledge with Python or similar language
Now some of these are more important than others in my opinion. For instance I don’t think the scripting knowledge was really necessary in all but a couple labs. That said, going to the class I met all of the requirements, but still felt a bit overwhelmed particularly on the first day. The main reason being, that while I understand python very well, I did not have a firm grasp of C or assembly. Much of the first day is spent getting everyone up to speed on things like C structures, OS Internals, and the Intel Architecture. This material would have been much easier to digest if I had a better understanding of the basic concepts before attending the class. So I would pick up
Windows Internals 6th Edition and
The Malware Analysis Cookbook, to brush up on that type of material if you are not already familiar.
While I mentioned the first day was a bit rough for me because I lacked some of that depth, the instructors quickly brought me and the rest of the class up to speed. It felt a lot like I remember USMC bootcamp, first they break you down showing you how much you don’t know, and then spend the rest of the week building you up until you feel like a rockstar.
As for the target audiences for this class, I think there are many various functional groups that could benefit. The obvious groups are of course your Incident Responders and Incident Analysts. Additionally though, I think that Reverse Engineers are probably the best suited for the class and gain the most from it. There are folks I would recommend not take the course. It was painful to hear some of the comments coming from some of the attendees that were having a hard time keeping up. If you do not understand basic command line usage, or how to setup a vm, or mount a drive in Linux, I would recommend spending some time on those topics first. Luckily, the Volatility team created a training preparation guide that dives into these topics and leads you towards deeper material as well. The preparation guide also includes a cheat sheet of Linux and Windows commands to assist those who may not be familiar with them. This guide is given 45 days before the course to give you adequate time to prepare.
Topics Covered
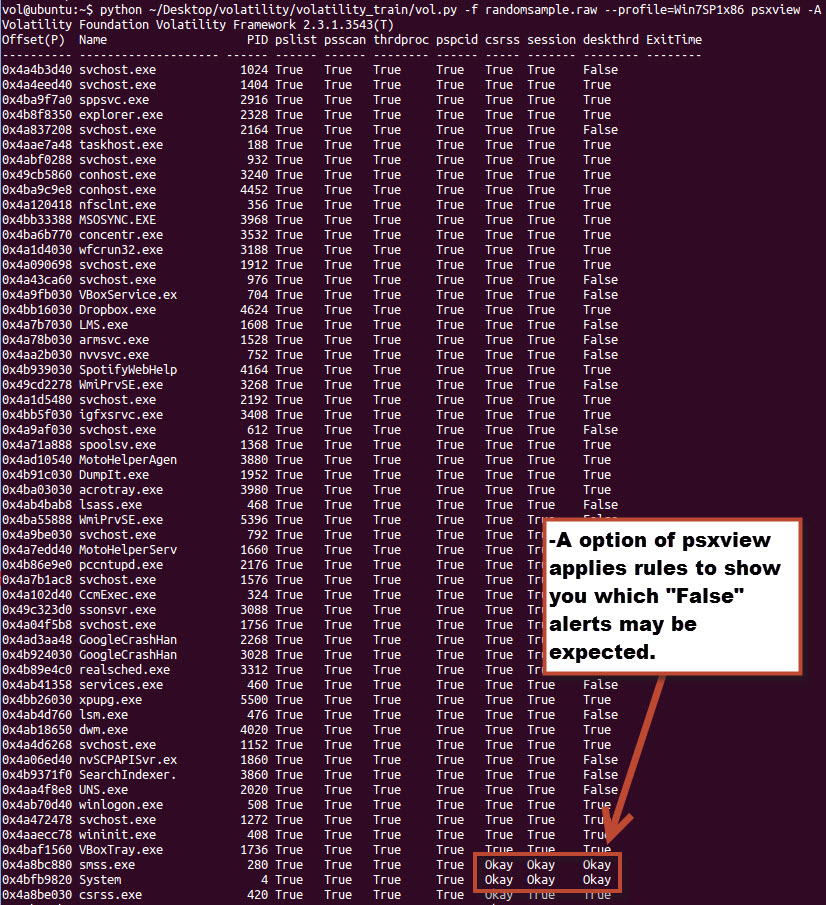
As I mentioned earlier in the review, I learned much more than I had anticipated in the course. Walking into the class I understood how to run plugins in volatility and interpret the results. Leaving the class I feel I have a much deeper understanding of the volatility framework and plugins, but more importantly Windows internals and Memory internals. For instance before class I knew it was bad if psxview showed a process as False under a category while True under another. Now I understand where in memory psxview is looking at for the processes and what it means if it shows in one place and not another. Additionally, based on the Windows internals knowledge passed in the class I understand why some processes will show “False” under normal circumstances.
To list off some of the topics covered:
• OS Internals, Intel/AMD Architecture
• Memory Acquisition
• Data Structures in Memory
• Windows Memory Analysis
• Process Analysis
• Threads and Handles analysis
• Code Injection
• Analyzing API Hooks
• Windows Services
• Networking
• Kernel Analyis
• Registry Analysis
• Truecrypt
• Timelines
• Etc.
While this is just a short listing of the topics that are covered, you are probably already starting to see how the class is much more than just a “running volatility” class.
Labs
In a technical class like this, the labs are of similar value as the course materials. In this class the labs took up about 25% of the class time. Structured like most classes, the labs reinforced the topics that were discussed in a specific module. To give you an example of what you can expect out of a lab:
You have been given a memory image of a machine that was believed to be infected with a keylogger. You must answer the following questions to determine the activity of the keylogger and its potential effects on the user.
1. Which process is suspicious and why?
2. Which file were keystrokes logged to?
3. What persistence mechanism was used by the keylogger?
4. Which aspects of the keylogger are modular? Hint: modularity is often accomplished by using DLLs exchanged without changing the main executable file.
5. What data was recorded by the keylogger on the infected computer? Hint: look at process memory. Is the data encoded? If so, can you decode it?
6. Which companies were targeted by the keylogger?
7. Which websites were visited, but filtered out by the keylogger?
8. (Bonus) How did the keylogger gain access to each keystroke?”
As you can probably tell from the example, the labs are realistic and ask the questions you would probably be focusing on if you came across the scenario in a case. I found all of the labs to be challenging and very rewarding. I have to admit there were a couple of labs that I needed to look at the answer guide for some help, but for the most part, while the labs were hard I was able to work my way through them. After each lab, the instructors would walk the class through a couple of methods to solve each of the questions. I found this particularly useful, as it allowed me to see several approaches to attack each type of problem. There was rarely a case where I arrived at the answers in the same exact way the instructors did.
Instructors
I have been in plenty of classes where I felt that the instructors did not know the material well enough to adequately teach it. This class does not suffer from the problem at all. The instructors for the course are the developers on the Volatility project, but their credentials don’t end there. The three instructors for the class I attended were Michael Ligh (
@iMHLv2), Andrew Case (
@attrc), Jamie Levy (
@gleeda). As most of you probably already know, all three of these instructors are prominent figures in the Information Security community, especially when it comes to Malware Analysis, Forensics, and Incident Response. There was not a single question asked in the class that they were not able to answer, and trust me when I say there were a few questions especially from
@xabean that I thought were going to be pretty rough to answer. The amount of knowledge they share between the three of them is truly intimidating.
Extras
As if the training wasn’t enough, the Volatility Team hands out a few extra goodies that you should probably be aware of as well. Some of this is stuff that is already out publically while others are only available to students of the class.
• Access to unreleased (as of yet) code and plugins
• A lab guide with answers. I already find myself using this while doing memory analysis, looking back to how I solved a particular problem in the class.
• A memory analysis checklist. Includes items such as “On Vista+, lsass.exe and services.exe parent should be wininit.exe (all in %system%)”
• A map of all the Volatility plugins
• Memscan – A python wrapper for volatility that applies some of the logic learned in the class automatically to call out suspicious items in a memory dump
•
Various scripts including a script to mbr parser created by (
@gleeda)
• A USB flash drive with all the extras on it
• A certificate of competition (40 CPE’s)
• A binder of all the slides from the class (over 1,000 pages).
• A prebuilt VM ready to roll for the labs
Conclusion
So as you can probably imagine by now, I highly recommend this class to anyone prepared for it. With a price lower than most SANS courses, this class is well worth the money and time spent on it. I can say my value as an Incident Responder increased drastically by taking this course. Keep an eye out for future posts where I plan to go over some plugins I am working on, as well as go over some analysis of memory samples. If you have a memory sample you want me to use for a walkthrough, feel free to reach out to me (
@TekDefense).
 Admin
Admin